---
layout: linguistics
title: linguistics/syntax
---
# morphosyntax
Morphology is the study of word formation. Syntax is the study of sentence formation.
Specifically, both morphology and syntax focus on **structure**.
The distinction between syntax and morphology varies cross-linguistically.
They can be considered to form an overarching **morphosyntactic** theory.
These notes are ordered in a way that I feel builds upon itself the best. This is not the order in which topics were covered in my syntax class, nor in my textbook. My syntax class covered Agree before Move, and my textbook deeply intertwined Merge with X'-theory and Move with Agree: and I think the both of them suffered a little bit pedagogically for that.
Certainly, all of syntax cannot be taught at once. Yet the desire to generalize and apply what one has learned to real-world examples is strong, and it is extraordinarily difficult to teach syntax in a way that builds upon itself naturally. This is my best attempt, but it will fall flat in places: when it does, I do recommend either skipping ahead or being content with temporarily (hopefully temporarily) not knowing what's going on.
Table of Contents
- History of Syntax
- A wrong approach: Phrase Structure Rules
- Morphology [SKS 2]
- Syntactic Categories [SKS 2.1]
- Compositionality [SKS 2.3]
- Headedness [SKS 2.4]
- [Merge, Part I](#merge-part-i)
- Binary Branching
- Constituency [SKS 3]
- Heads, Specifiers and Complements
- [Silent Heads](#silent-heads)
- [Notation](#notation)
- X'-theory [SKS 6]
- [Bare Phrase Structure](#bare-phrase-structure) [n/a]
- Lexical Entries [SKS 6.8]
- [Minimalism](#minimalism) [n/a]
- [Merge, Part II](#merge-part-ii)
- [Projection](#projection) [SKS 5]
- Selection [SKS 8]
- [Move, Part I](#move-part-i) [SKS 8]
- [Affix Hopping](#affix-hopping)
- Verb Raising
- Subject-Auxiliary Inversion
- Head Movement [SKS 8.3]
- Move, Part II
- Wh- Movement [SKS 10]
- Topicalization
- Phrasal Movement
- [Subject Raising](#subject-raising) [SKS 12.4]
- Agree
- Theta Roles [SKS 6.8.1]
- Locality
- [Binding](#binding) [SKS 7]
- Raising & Control [SKS 9]
- Advanced Syntax
- [On languages other than English](#on-languages-other-than-english)
- Negation
- Ellipsis
- Shifting
- Scrambling
- Parsing
- References
> Be warned! These notes are incomplete and almost certainly somewhat inaccurate. Proceed at your own risk.
## history
### a wrong approach: phrase structure rules
## morphology
### syntactic categories
### compositionality
### headedness
## Merge, Part I
We concluded the following from our excursion into morphology:
- words are composed of *morphemes*
- morphemes come in *categories*
- morphemes *combine in a regular fashion*
- morphemes can be *silent*
Surprisingly (or unsurprisingly), we shall see that these ideas generalize to sentence structure as a whole.
### constituency
### heads, specifiers, and complements
### silent heads
Why are proper names $D$s? Why is it possible to say either *I moved the couches* and *I moved couches*, but only possible to say *I moved the couch* and not *I moved couch*? Why is the infinitive form of a verb identical to the present, in some cases?
These inconsistencies can be all addressed by one (strange) concept: the idea of *silent morphemes*, invisible in writing and unpronounceable in speech. We represent such morphemes as ∅, and so may write the earlier strange sentence as *I moved ∅-couches*.
These silent morphemes are extremely useful to our syntactic analyses. Consider our examples above. With silent morphemes, we can describe the verb *moved* as taking in two $D$s as arguments: *I* and *couches*. Without silent morphemes, we would have to account for both $D$ phrases and $N$ phrases as arguments, duplicating our lexical entry, destroying the structural similarity to *I moved the couches*, and ultimately duplicating our work.
```latex
\begin{forest}
[V
[D [I, roof]]
[V_D
[V_{D,D} [moved]]
[D
[D_N [∅]]
[N [couches]]]]]
\end{forest}
```
So silent morphemes are extremely handy. But: what is stopping us from using an *excess* of silent morphemes? After all, if they're just morphemes, they can go anywhere. And if they're silent, we can't observe *where* they go. We will revisit this topic, but for know, we shall consider the list of silent morphemes to be very finite, and their use regular and a rarity.
p-features | f-features | s-features
-----------|------------|-----------
the | $D_{N}$ | definite
a | $D_{N (-plural)}$ | indefinite
∅ | $D_{N (+plural)}$ | indefinite
p-features | f-features | s-features
-----------|------------|-----------
will | $T_{D,V}$ | future
-ed | $T_{D,V}$ | past
∅ | $T_{D,V}$ | present
to | $T_{D,V}$ | infinitive
These tables are using notation and language formally introduced at the end of the next section. Ignore them for now.
## notation
So far, we've been discussing syntax and giving examples using somewhat informal notation. We now formalize this notation.
### X'-theory
...
### Bare Phrase Structure
**Bare Phrase Structure** (BPS) is a more modern notation that does away with much of the notational cruft of X'-theory. Instead of bar levels and distinctions between bar levels and "phrases", we simply put the *formal features* of our lexicon in the chart itself and only indicate the *types* of phrases. Whether a phrase has yet to close yet or not (previously indicated by a 'bar) is now indicated by whether there are any unsatisfied selectional requirements on the phrase label.
**Head-Initial Phrases**
![`[X [X_Y (head)] [Y (complement)]]`](head-initial.png)
LaTeX
```forest
\begin{forest}
[$X$
[$X_Y$ [(head)]]
[$Y$ [(complement)]]]
\end{forest}
```
**Head-Final Phrases**
![`[X [Y (complement)] [X_Y (head)]]`](head-final.png)
LaTeX
```forest
\begin{forest}
[$X$
[$Y$ [(complement)]]
[$X_Y$ [(head)]]]
\end{forest}
```
Recall that adjuncts are able to appear on either side of their head. Also recall that adjuncts *select* for their head. We indicate this in our labeling: adjuncts, like heads, have their selectional requirements marked, but do not propagate their type. While certain constructions may lead to notational ambiguity - an adjunct and a head of the same type, specifically - this is rare enough (only really occurring with adverbs) that we take the convenience of BPS notation regardless.
**Left Adjuncts**
![`[X [Y_X (left adjunct)] [X (head)]]`](left-adjunct.png)
LaTeX
```forest
\begin{forest}
[$X$
[$Y_X$ [(left adjunct)]]
[$X$ [(head)]]]
\end{forest}
```
**Right Adjuncts**
![`[X [X (head)] [Y_X (right adjunct)]]`](right-adjunct.png)
LaTeX
```forest
\begin{forest}
[$X$
[$X$ [(head)]]
[$Y_X$ [(right adjunct)]]]
\end{forest}
```
As a reminder, English is not consistently head-initial. Subjects ("specifiers") in English appear before the verb, breaking this convention. This common structure is represented as the following:
![`[X [Y (specifier)] [X_Y [X_{Y,Z} (head)] [Z (complement)]]]`](english-specifier.png)
LaTeX
```forest
\begin{forest}
[$X$
[$Y$ [(specifier)]]
[$X_Y$
[$X_{Y,Z}$ [(head)]]
[$Z$ [(complement)]]]]
\end{forest}
```
The lexicon and structure are blended in bare phrase structure. This is useful, and allows us to indicate more specific selectional requirements on the tree itself.
...
It cannot be emphasized enough that notational conventions are *just that*: notational conventions. There's nothing stopping us from exclusively using X'-notation or exclusively using BPS, and the syntactic concepts they describe are *not* tied to any specific notation. I will pretty much exclusively use BPS going forth as I like it a whole lot more.
### lexical entries
We have stated that Bare Phrase Structure pulls aspects of the lexicon directly into the syntax tree. But what is a lexicon?
A **lexicon** is a language speaker's internal collection of lexical entries. But what is a lexical entry?
What exactly a lexical entry contains is up to some debate. The English language consists of (significantly) upwards of 400,000 words. How humans can hold that much information in our mind, and retrieve it so quickly? This is biologically interesting, and there are arguments for what such entries should and should not contain that come from such fields. For our purposes, we will focus entirely on syntactic analysis, and ignore biological motivations. We treat a **lexical entry** as containing the following information about an associated morpheme:
- phonetic features (**p-features**): how the word is pronounced
- With our focus on syntax, we shall simply consider this the standard written representation of the morpheme. But it should really be written in IPA.
- formal features (**f-features**): the type of the morpheme and what types it selects, if any
- These are often written directly on our tree in BPS. While most often they are simply the types of the arguments - heads can select for much more granular features, i.e. -tense, +animacy, etc.
- semantic features (**s-features**): the role of the entry and its arguments in the sentence
- Not all lexical entries have s-features. For tense/aspect/etc, these are their appropriate tense/aspect/etc. For verbs, these are typically *theta roles* (which we shall address later).
This is the formalism expressed in our tables earlier.
Heads select for the features of their complements and project their own features.
Adjuncts select for the features of their heads but do not project their features.
## Minimalism
[Minimalism](https://en.wikipedia.org/wiki/Minimalist_program) is a *program* that aims to reduce much of the complexity surrounding syntactic analysis. While our theories may end up providing for adequate analyses of natural languages, this is not enough. Phrase structure rules, too, were *adequate*: yet we rejected them for their sheer complexity. If we can explain what we observe in a simpler framework, *we should adopt that framework*. Much of modern advancements in syntactic analysis have come out of Minimalism: the notation of bare phrase structure, in particular.
As with most Chomskyan theories: Minimalism has a *strong* focus on natural language facilities. A core thesis is that *"language is an optimal solution to legibility conditions"*. I don't find this all too interesting, so I won't get much into it, and instead will focus on the definitions and usage of the basic operations rather than the motivation for them.
Modern Minimalism considers into three *basic operations*: Merge, Move, and Agree. All that we will discuss can fall into one of these basic camps.
## Merge, Part II
Merge(α, β) is a function that takes in two arguments of type α and β and outputs a single node of either type α or β.
Merge is *the* fundamental underlying aspect of syntax and arguably language as a whole. Compositionality, headedness, movement (in some camps), and a whole lot more can be considered to be rolled into it.
### projection
We have talked casually much about the idea of heads "projecting" their type, and this informing the syntactic structure of parsed sentences. We now formally discuss this.
The **projection principle** states that *the properties of lexical items must be satisfied* (chief among lexical properties being selectional properties). This is a simple statement, but has profound implications: in particular, when we observe that properties of lexical items appear to *not* be satisfied, there is likely something deeper going on.
...
### selection
## Move, Part I
Move(α, β)
All movement falls into one of the following categories:
- Head Movement
- T-to-V: affix hopping
- V-to-T: verb raising (was / be)
- T-to-C: subject-auxiliary inversion
- Phrasal Movement
- A-movement (argument movement)
- subject raising
- A'-movement (non-argument movement)
- topicalization
- wh-movement
We shall visit these each in depth.
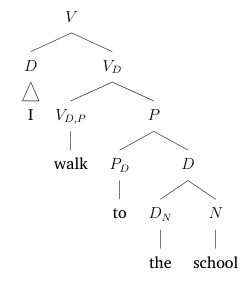
### affix hopping
LaTeX
```forest
\begin{forest}
[$V$
[$D$ [I, roof]]
[$V_D$
[$V_{D,P}$ [walk]]
[$P$
[$P_D$ [to]]
[$D$
[$D_N$ [the]]
[$N$ [school]]]]]]]
\end{forest}
```
So far, we have not dealt with tense. We have diagrammed sentences with verbs in present and past forms by entirely ignoring their *-s* and *-ed* affixes. But tense is an aspect of grammar just like anything else, and writing it off as purely semantic does no good to anyone. Indeed, the English future having its tense marker *will* as a free-standing morpheme strongly suggests that we have to treat tense as a syntactic category in its own right, and not just as an inflectional property of verbs.
A tense needs a *subject*. This is often stated as the **extended projection principle**, for how fundamentally it influences the structure of sentences. For now, we'll consider the verb to no longer be in charge of selecting the subject, and leave it to the tense. This is not in fact accurate - as we will see at the end of this section - but it is a simplification we shall make for the time being.
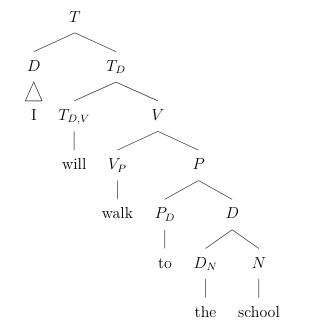
LaTeX
```forest
\begin{forest}
[$T$
[$D$ [I, roof]]
[$T_D$
[$T_{D,V}$ [will]]
[$V$
[$V_P$ [walk]]
[$P$
[$P_D$ [to]]
[$D$
[$D_N$ [the]]
[$N$ [school]]]]]]]
\end{forest}
```
While *will* is straightforward: what about *-ed* and and *-s*? These markers are *suffixes* (bound morphemes) and are directly attached to the end of the verb. Attempts to diagram these with our current knowledge of syntactic structure begin and end with nonsense. However, consider *will*: on analogy with *will*, it should follow that the tense markers *-ed* and *-s* should actually be in the same position, given our diagramming of *will* works without issue. But how can this be?
In this section, we introduce the idea of *movement*: that certain portions of sentences can *move* in certain *constrained* fashions around the rest of the sentence, almost (but not quite) *copying* themselves to other places. We saw hints of this with our constituency tests earlier producing grammatically valid but unanalyzable sentences. For now, we shall simply assert that tense suffixes move on analogy with *will* without asserting anything about movement in general. We shall cover constraints on movement shortly.
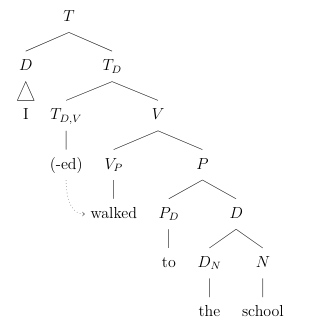
LaTeX
```forest
\begin{forest}
[$T$
[$D$ [I, roof]]
[$T_D$
[$T_{D,V}$ [(-ed), name=tense]]
[$V$
[$V_P$ [walked, name=walk]]
[$P$
[$P_D$ [to]]
[$D$
[$D_N$ [the]]
[$N$ [school]]]]]]]
\draw[->,dotted] (tense) to[out=south,in=west] (walk);
\end{forest}
```
(we say that *-ed* leaves a **trace** when moving to *walk*. we denote this here with *(-ed)*, but another common notation is to write *t*.)
English's first-person present does not inflect the verb, and so we must introduce a null $T$. A similar example is given for the present tense in the third person, which does have an explicit tense marker.
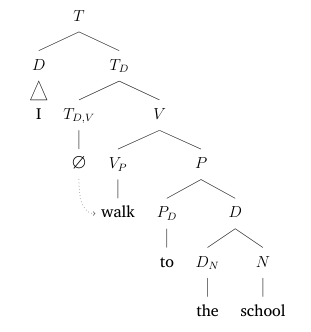
LaTeX
```forest
\begin{forest}
[$T$
[$D$ [I, roof]]
[$T_D$
[$T_{D,V}$ [∅, name=tense]]
[$V$
[$V_P$ [walk, name=walk]]
[$P$
[$P_D$ [to]]
[$D$
[$D_N$ [the]]
[$N$ [school]]]]]]]
\draw[->,dotted] (tense) to[out=south,in=west] (walk);
\end{forest}
```
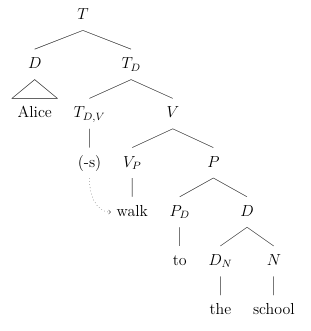
LaTeX
```forest
\begin{forest}
[$T$
[$D$ [Alice, roof]]
[$T_D$
[$T_{D,V}$ [(-s), name=tense]]
[$V$
[$V_P$ [walk, name=walk]]
[$P$
[$P_D$ [to]]
[$D$
[$D_N$ [the]]
[$N$ [school]]]]]]]
\draw[->,dotted] (tense) to[out=south,in=west] (walk);
\end{forest}
```
This now makes our top-level phrase type $T$ instead of $V$. It will not remain so for very long, as we shall see in Agree.
### verb raising
### subject-auxiliary inversion
### head movement
## Move, Part II
### wh-movement
### subject raising
Consider the following sentence: *Alice will speak to the assembly*. With our current knowledge of syntax, we would diagram it as so:
![`[T [D Alice] [T_D [T_{D,V} will] [V [V_P speak] [P [P_D to] [D [D_N the] [N assembly]]]]]]`](no-subject-movement.png)
LaTeX
```forest
\begin{forest}
[$T$
[$D$ [Alice, roof]]
[$T_D$
[$T_{D,V}$ [will]]
[$V$
[$V_P$ [speak]]
[$P$
[$P_D$ [to]]
[$D$
[$D_N$ [the]]
[$N$ [assembly]]]]]]]
\end{forest}
```
The $D$ *Alice* here is the subject. While replacing it with some $D$s produces grammatical sentences ex. *The prime minister will speak to the assembly*: this is not true of all $D$s. Slotting in inanimate $D$s like *Time will speak to the assembly* and *Knowledge will speak to the assembly* produces grammatically unacceptable sentences. So there is some *selection* occurring somewhere in the sentence that wants a particular *feature set* (f-features) from the subject $D$, specifically, animacy.
Observe, however, that our tree structure suggests that $T$ - and only $T$ - is involved in the selection of $Alice$ as the subject, given locality of selection and the extended projection principle. But this can't be quite right. Plenty of other sentences involving the $T$ *will* are just fine with inanimate subjects: *Time will pass*, *Knowledge will be passed on*, etc. (Notice that *Alice will pass* and *Alice will be passed on* are similarly ungrammatical). How do we reconcile this?
We now introduce the idea of **subject raising** / $vP$ shells. Our observations above point towards the $V$ of the sentence rather than the $T$ selecting for the subject $D$ - somehow. This selection would break our guiding principle of locality of selection. But this behavior *does* occur, and as an empirical science we must adjust our theory accordingly. Can we extend our model to explain this, *without* modifying the locality of selection that has been so useful thus far? We can, indeed, with movement, and illustrate so in the following tree.
![`[T [D Alice] [T_D [T_{D,V} will] [V [D (subj)] [V_D [V_{D,P} speak] [P [P_D to] [D [D_N the] [N assembly]]]]]]]`](subject-movement.png)
LaTeX
```forest
\begin{forest}
[$T$
[$D$ [Alice, roof, name=Alice]]
[$T_D$
[$T_{D,V}$ [will]]
[$V$
[$D$ [(subj), roof, name=subj]]
[$V_D$
[$V_{D,P}$ [speak]]
[$P$
[$P_D$ [to]]
[$D$
[$D_N$ [the]]
[$N$ [assembly]]]]]]]]
\draw[->,draw opacity=0.5] (subj) to[out=west,in=south] (Alice);
\end{forest}
```
So we say that *Alice* is originally selected by the $V$ and *moves* to its surface position in the $T$. *Alice* satisfies the projection principle by being selected by the $V$, satisfies the extended projection principle by fulfilling the role of the subject for the $T$, and satisfies locality of selection by being in complement and specifier position for the $V$ and the $T$, respectively. Our concept of movement allows *Alice* to play **both** roles at the same time. This does mean that every tree diagram we have drawn up until now is inaccurate, and that almost every tree we draw going forward will have to have this somewhat redundant subject raising. This is a fine tradeoff to make in exchange for accurately describing previously-unclear syntactic behavior.
This subject raising is an example of **A-movement** (argument movement). A-movement exists in contrast to **A'-movement** (movement to a non-argument position), which is responsible for wh-movement and topicalization: two topics that we shall touch on shortly.
### small clauses
## Agree
### theta roles
### locality
### binding
How do pronouns work?
First, some definitions. We distinguish several classes of pronouns:
- **anaphors**: *reflexive* and *reciprocal* pronouns i.e. *herself*, *each other*, ...
- **personal pronouns**: *her*, *him*, *they*, *it*, ...
- **possessive pronouns**: *ours*, *theirs*, *hers*, *his*, ...
- ...
Every pronoun (pro-form, really) has an **antecedent**: that is, the phrase or concept it is in *reference* to. In contrast to pronouns, we also have **r-expressions**: an **independently referential** expression. These are names, proper nouns, descriptions, epithets, and the like: ex. *Alice*, *British Columbia*, *the man on the corner*, *the idiot*, etc; and have no antecedent.
We say that a node and another node are **coreferential** (or **co-indexed**) if they refer to the same concept or entity. On tree diagrams, we often refer to this with numerical ($_0$, $_1$, ...) or alphabetical ($_i$, $_j$, $_k$) subscripts. (Though we could also indicate this with arrows, we prefer to reserve those for movement, so as to not clutter our diagrams too much.) This is a useful notion when it comes to pronouns.
...
The theory of binding operates under three fundamental principles.
- **Principle A**: an anaphor must be bound in its domain.
- **Principle B**: a (personal) pronoun must be free in its domain.
- **Principle C**: an r-expression may never be bound.
Our principles imply various things. Principle A implies that:
- a reflexive must be *coreferential* with its antecedent
- (agreeing in person, number, and gender)
- the antecedent of a reflexive must *c-command* the reflexive
- the reflexive and its antecedent must be *in all the same nodes* that have a subject
### raising and control
Consider the following sentences:
- *Alice seems to sleep often.*
- *Alice hopes to sleep often.*
With our current knowledge, we would diagram these sentences near-identically. Yet a closer investigation reveals that they are in fact deeply structurally different.
- *It seems Alice sleeps a lot.*
- \* *It hopes Alice sleeps a lot.*
## Advanced Syntax
### on languages other than english
We have so far approached our discussion of syntax entirely from the point of view of the English language. All of our motivations - our rationales, our counterexamples - have been given and centred around English. This begs the question: just how much of this *holds*, cross-linguistically? What of all the other wide and varied languages of the world - which, clearly, our frameworks must have been built not only to accommodate but to represent *well*, given we are discussing them now, more than fifty years after the Chomskyian revolution and more than a century after the field of linguistics recognized its Indo-European biases?
We have discussed some principles that, clearly, cannot be a feature of all natural languages: like do-support. However, other concepts - like the Subjacency Condition - seem possibly broad enough to be applied across a variety of languages. Is that true? Is *anything* broad enough? (Alternatively: does a [universal grammar](https://en.wikipedia.org/wiki/Universal_grammar) exist?)
This notion of *principles* that occur for some languages and do not occur for others forms what is either the framework of *Principles and Parameters*, or *Government and Binding Theory*. I do not understand the difference between them, and suspect what is above to be a mixture of both as neither were explicitly mentioned. Nevertheless, everything given here is for English, not some cross-linguistic model of the mind. English remains useful by virtue of being mine and many's L1 language - and by being such a *mess* of a language that its structure cannot be explained away trivially.
### negation
### ellipsis
## References
- ✨ [An Introduction to Syntactic Analysis and Theory](https://annas-archive.org/md5/11bbf70ff9259025bc6985ba3fa4083b)
- ✨ [The Science of Syntax](https://pressbooks.pub/syntax/)
- MIT 24.902: [2017](https://web.mit.edu/norvin/www/24.902/24902.html), [2015](https://ocw.mit.edu/courses/24-902-language-and-its-structure-ii-syntax-fall-2015/), [2003](https://ocw.mit.edu/courses/24-902-language-and-its-structure-ii-syntax-fall-2003/)